LED 显示屏
更新: 6/2/2025 字数: 0 字 时长: 0 分钟
在前一节中,我们了解了如何在 LED 点阵面板上显示一行文字。在本节中,我们将学习如何用 LED 显示屏显示更多的内容。

像素点和分辨率
想要了解屏幕的工作原理,首先需要了解像素点的概念。像素点是屏幕上的图像的基本构建单元。任何一辐画面,实际上都是由无数的像素点拼凑出来的。
在显示器的背光下,每个像素点具有特定的颜色值,通常使用红、绿、蓝(RGB)的值组合而来。当每个像素点显示相应的颜色,就有了完整的画面。
而我们耳熟能详的分辨率,指的就是像素点的数目。同样大小的屏幕,单个像素点越小,总的像素点数量越多,分辨率越高,显示的图像就更清晰锐利。


刷新率
刷新率,通常称为“帧率”或“刷新频率”,是各种显示技术,包括监视器、电视和数字屏幕的重要参数。它定义了屏幕上的图像每秒重新绘制或刷新的次数。
刷新率以赫兹(Hz)为单位,表示显示器每秒更新其显示内容的次数。例如,60Hz的刷新率意味着显示器每秒更新图像60次。刷新率对视频、动画和游戏中的动画流畅度有重要影响。更高的刷新率可以使这些视觉效果显得更流畅和更生动。
在过去,显示器的最常见刷新率为60Hz,这是由交流电能系统的频率决定的。然而,现代显示器通常支持更高的刷新率,例如120Hz、144Hz、240Hz,甚至360Hz。
高刷新率可以显著减少运动模糊,使屏幕上的快速移动物体显得更加清晰,游戏体验更流畅。但高刷新率也需要内容和驱动硬件的支持。比如,要体验120Hz的游戏,需要具备能够以每秒产生120帧的控制器或计算机。而且,大多数电影和电视节目传统上以24fps的帧率拍摄,由于采用了3:2拉伸技术,这在60Hz显示器上看起来非常流畅,但可能无法充分利用更高刷新率。
LED 显示屏 v.s. LCD 显示屏
这两种类型的显示屏的主要区别在于背光不同。LED 屏幕使用发光二极管作为背光,而 LCD 使用荧光背光。LED 显示屏和传统的 LCD 显示屏相比,拥有诸多优点。

首先,LED 显示屏的每个像素点都是独立的,所以它不用像 LCD 屏幕那样,一旦打开就要点亮整个背光层,无形中节约了能耗。
另外,正因为 LED 显示屏的每个像素点是独立发光的,所以可以实现近乎无无限的对比度。对比度指的是画面黑白明暗的亮度比值,对比度越高的画面看上去色彩越浓郁。LED 屏幕可以直接关闭相应像素点的背光,提升对比度,从而提高画质。

还有,因为 LED 显示屏可以快速切换每个像素点的颜色,所以它显示的动态画面更清晰。LED 显示屏的亮度也更高,在阳光下也能清晰显示,所以适合在户外使用,例如商店的招牌和广告牌。
字符编码标准
文本数据是通过字符编码转化成计算机能够理解和处理的二进制编码。这些的编码标准,确保了不同语言、文字和符号在计算机系统中的一致表示。
一些常见的字符编码标准包括:
- ASCII(美国信息交换标准代码):最早的字符编码标准,使用 7 位二进制编码,覆盖了基本的英文字母、数字和符号。
- Unicode:通用字符编码标准,旨在统一世界上几乎所有的字符集和符号。它为每个字符分配了唯一的代码点,支持多种编码方式。
- UTF-8、UTF-16 等:Unicode 的编码方案,用于将 Unicode 代码点映射为可存储和传输的字节序列。
- ISO-8859 系列:涵盖了多种欧洲语言字符集的编码标准。
- GBK、GB2312 等:中文字符集的编码标准,用于表示汉字和中文字符。
字符编码标准在文本处理、网页显示、软件开发和国际化方面起着关键作用。了解不同的字符编码标准可以帮助确保文本数据在不同系统和平台上的正确传输和显示。
1. ASCII(美国信息交换标准代码)
ASCII 码是一种在早期计算机系统中广泛使用的字符编码标准。它主要设计用于英语文本,因此其他语言的字符或特殊符号并未包含在原始的 ASCII 字符集中。
ASCII 码使用 7 位二进制表示,这意味着它可以表示多达 128 个不同的字符(2^7)。最高位(第 8 位)在 ASCII 中未被使用,并且在早期通信系统中通常用于奇偶校验。
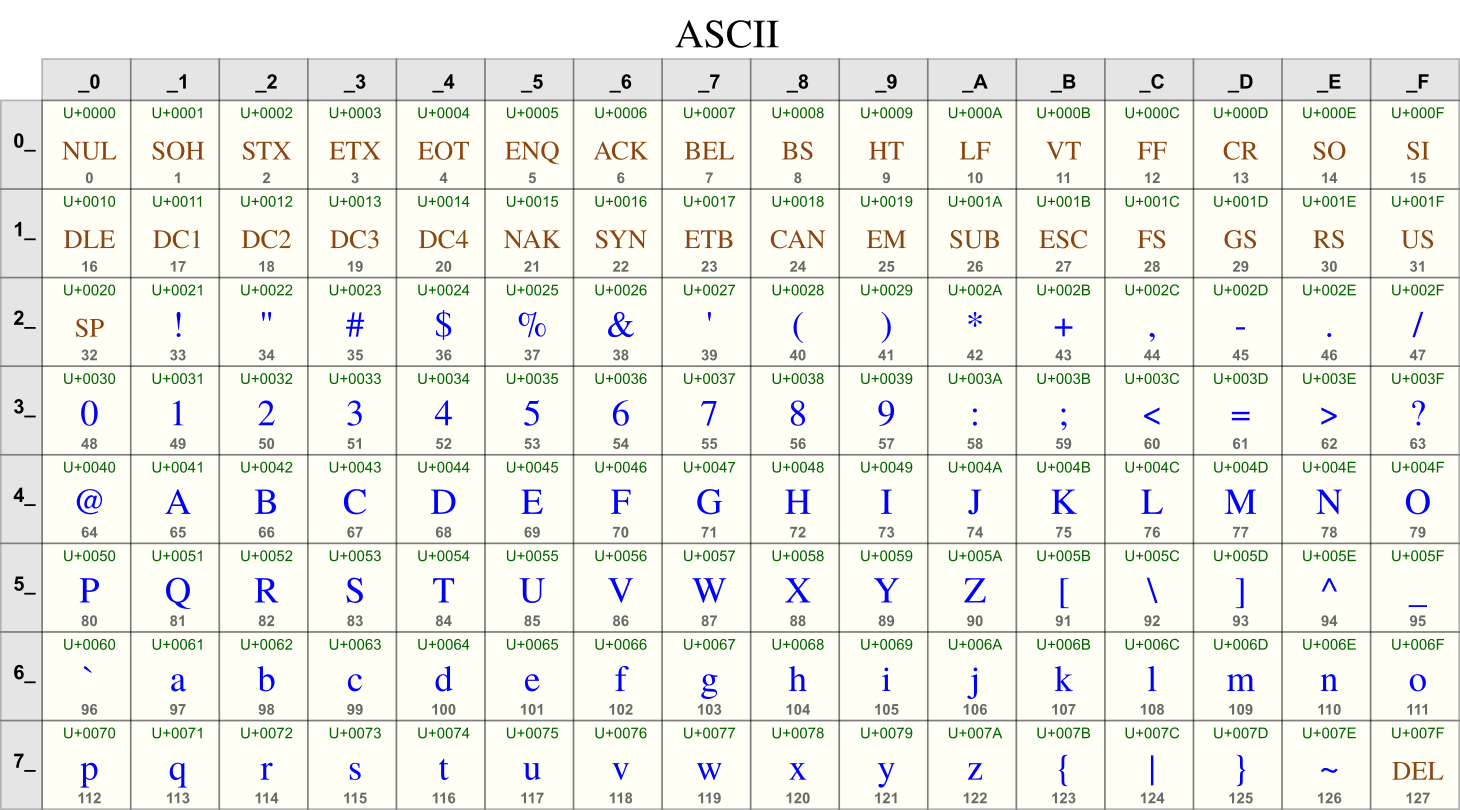
尽管 ASCII 在字符编码方面是一个重要的里程碑,但其限制为 128 个字符使其无法表示来自各种语言和文字的字符。随着计算机变得更加国际化,对更全面的字符编码标准的需求促使了 Unicode 的发展,Unicode 可以表示世界各地几乎所有语言和文字的字符。
2. Unicode
Unicode 的理念是为每个字符和符号分配一个“唯一码点”,使每个字符都有一个独特的位置。
设计上,前 256 个编码与 ISO-8859-1 完全相同,以便轻松地转换现有的西方文本。在本页的代码图表中,您可以看到每个字符的 Unicode 码点(U+xxxx,其中“xxxx”是十六进制数)。
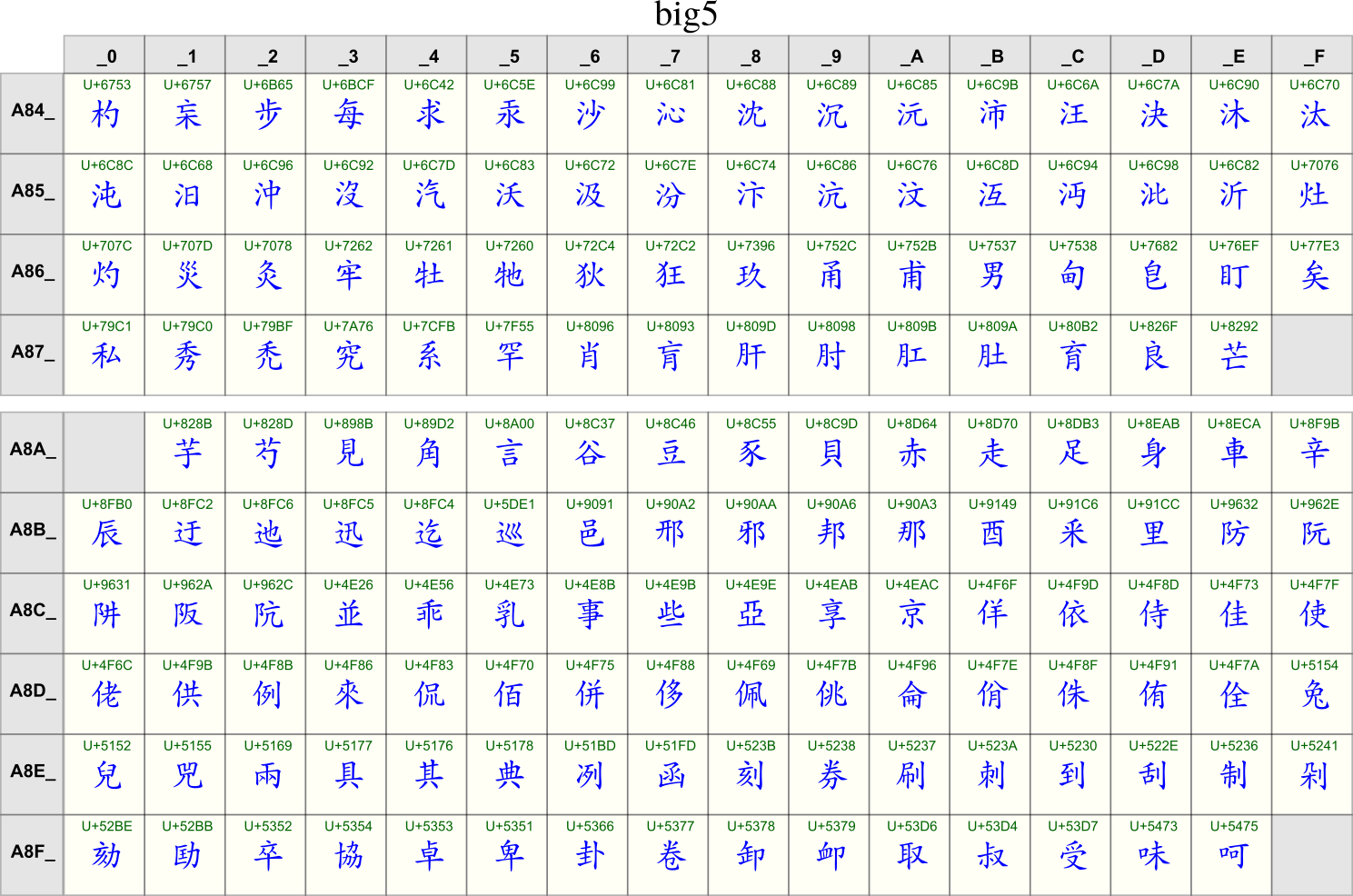
Unicode 空间被分成了各个块,每个块的代码分别对应不同的语言。Unicode 字符还包括标点符号、数学和音乐符号、表情符号等等。
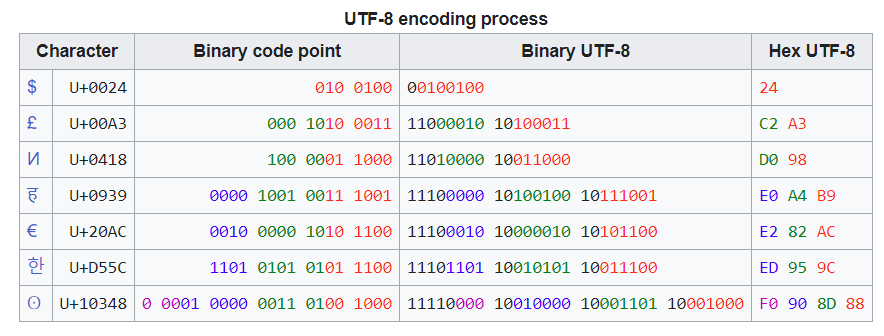
3. UTF-8 编码方式
UTF-8 是 Unicode 的编码方式之一。它有一个很好的特性,就是对于普通的 ASCII 字符(0x00 到 0x7F),它的编码与 ASCII 完全相同。

前 128 个码点(ASCII)需要一个字节。接下来的 1,920 个码点需要两个字节进行编码,这涵盖了几乎所有拉丁字母表的其余部分。剩余的 61,440 个码点属于基本多语言平面(BMP),需要三个字节进行编码,包括大多数汉字、日语和韩语字符。而其他 Unicode 平面中的 1,048,576 个码点需要四个字节进行编码,其中包括表情符号(象形符号)、较少使用的 CJK 字符、各种历史脚本和数学符号。
一个“字符”可能需要超过 4 个字节,因为它由多个码点组成。例如,一个国旗字符需要 8 个字节,因为它是由两个来自 BMP 以外的 Unicode 标量值构成的。
下图是 UTF-8 编码方式的举例。比如 U+0024,只需要在原码点前加 0,组成一个字节,数值也不变;而 U+00A3,就需要两个字节表示。首先要将原码点高位的 5 位标成绿色,低位的 6 位标成红色,再分别加上前缀 110 和 10,组成两个完整的字节。以此类推:
字体
字体也是以二进制格式编码的,以便计算机可以读取和理解。字体文件通常使用特定的文件格式,每种格式都有自己的规范和结构,用于存储字符的编码映射和图形数据。
字符的编码映射,指的是将字符的编码或 Unicode 码点,对应到字体的字符图形数据。字符图形数据,包含了外观、大小、位置等信息。这些数据以矢量图形的形式存在,描述了字符的外观。计算机读取到这些字形数据后,就可以将其绘制出来,形成了特定的字体样式。
